Sebagai contoh ada artikel yang hanya membahas pengertian hadoop saja, manfaat hadoop saja, sejarah hadoop saja, cara kerja hadoop saja, cara install hadoop saja, dan sebagainya.
Melalui artikel ini saya mencoba menyajikan dalam satu kali bahasan tentang apa itu hadoop, artikel ini saya tujukan untuk rekans yang antusias belajar terkait hadoop dan menginginkan kemudahan dalam proses belajar tentang hadoop.
Saya sempat berfikir... apakah dengan saya gabungkan menjadi satu artikel, malahan akan membosankan untuk rekans yang membacanya? karena artikel yang terlalu panjang.
Namun setelah saya melihat ke dalam diri saya, yang merasa kurang nyaman dengan bahasan yang terpotong-potong ketika proses belajar tentang Hadoop. Saya merasa akan sangat membantu jika ada yang bisa memberikan bahasan tersebut dalam satu artikel saja, namun dengan bahasa yang ringkas.
Atas dasar itulah saya coba buat artikel ini, sehingga rekans yang sama-sama belajar seperti saya mendapatkan kemudahan untuk memahami konsep dasar apa itu hadoop.
Bagaimana dengan rekans? jika merasa sama dengan yang saya rasakan dapat melanjutkan membacanya sampai akhir.
 |
| Hadoop Adalah |
1. Pengertian Hadoop
Hadoop adalah framework open source berbasis Java di bawah lisensi Apache untuk mensupport aplikasi yang jalan pada Big Data. Hadoop berjalan pada lingkungan yang menyediakan storage dan komputasi secara terdistribusi ke kluster-kluster dari komputer/node.2. Sejarah Singkat Hadoop
Asal mula hadoop muncul karena terinspirasi dari makalah tentang Google MapReduce dan Google File System (GFS) yang ditulis oleh ilmuwan dari Google, Jeffrey Dean dan Sanjay Ghemawat pada tahun 2003.Proses developmen dimulai pada saat proyek Apache Nutch, yang kemudian baru dipindahkan menjadi sub-proyek hadoop pada tahun 2006. Penamaan menjadi hadoop adalah diberikan oleh Doug Cutting, yaitu berdasarkan nama dari mainan gajah anaknya.
3. Manfaat Hadoop - mengapa hadoop diperlukan?
Untuk menjawab pertanyaan mengapa hadoop diperlukan, saya coba jabarkan dalam bentuk perbandingan antara pendekatan tradisional (RDBMS) dengan solusi yang ditawarkan oleh hadoop.3.a Pendekatan Tradisional
Dalam pendekatan ini, suatu perusahaan akan memiliki komputer skala enterprise (High-End Hardware) untuk menyimpan dan mengolah data besar. Data besar tersebut akan disimpan dalam RDBMS skala enterprise seperti Oracle Database, MS SQL Server atau DB2.Dibutuhkan software canggih untuk dapat menulis, mengakses dan mengolah data besar tersebut dalam rangka kebutuhan analisis.
 |
| Pendekatan Tradisional |
- Kesulitan menggolah data berukuran sangat besar (Big Data), misal 1 file berukut 500 GB, 1 TB, dst.
- Keterbatasan Hardware terhadap kemampuan pengolaha data yang besar, sehingga Waktu akses semakin lama ketika memproses data yang semakin sangat besar
- Hanya bisa data bersifat tabular
3.b. Solusi Hadoop
Dalam pendekatan ini Hadoop mendukung pemprosesan secara terdistribusi ke kluster-kluster dari komputer. Hadoop didukung oleh dua komponen utama.- HDFS merupakan sistem penyimpanan/storage terdistribusi, yang melakukan proses pemecahan file besar menjadi bagian-bagian lebih kecil kemudian didistribusikan ke kluster-kluster dari komputer.
- MapReduce merupakan algoritma/komputasi terdistribusi
 |
| Solusi Hadoop |
Kelebihan Solusi Hadoop dengan didukung oleh dua komponen utama tersebut:
- Sangat baik untuk mengolah data berukuran besar, bahkan untuk ukuran 1 TB sekalipun
- Lebih cepat dalam mengakses data berukuran besar
- Lebih bervariasi data yang bisa disimpan dan diolah dalam bentuk HDFS
Namun dengan kelebihan tersebut bukan berarti tanpa kekurangan, berikut ini limitasi-nya.
- Tidak cocok untuk OLTP (Online Transaction Processing), di mana data dapat diakses secara randon ke Relational Database
- Tidak cocok untuk OLAP (Online Analytic Processing)
- Tidak cocok untuk DSS (Decission Support System)
- Proses update tidak bisa untuk dilakukan (seperti pada hadoop 2.2), namun untuk Append bisa dilakukan
Berdasarkan beberapa limitasi tersebut dapat disimpulkan bahwa Hadoop adalah sebagai Solusi Big Data untuk pengolahan data besar, menjadi pelengkap OLTP, OLAP, dan DSS, jadi hadoop bukan untuk menggantikan RDBMS. Saya rasa untuk saat ini, namun bisa jadi suatu saat hadoop bisa lepas dari limitasi tersebut
4. Arsitektur Hadoop atau Ekosistem Hadoop
Framework hadoop terdiri atas empat modul/komponen utama.- Hadoop HDFS adalah sebuah sistem file terdistribusi.
- Hadoop MapReduce adalah sebuah model programming/Algoritma untuk pengelolaan data skala besar dengan komputasi secara terdistribusi
- Hadoop YARN adalah sebuah platform resource-management yang bertanggung jawab untuk mengelola resources dalam clusters dan scheduling
- Hadoop Common adalah berisi libraries dan utilities yang dibutuhkan oleh modul Hadoop lainnya.
Semenjak tahun 2008 framework hadoop bukan hanya empat modul utama tersebut namun merupakan kumpulan modul open source seperti Hive, Pig, Oozie, Zookeeper, Flume Sqoop, Mahout, Hbase, Ambari, Spark, dsb.
Sekelompok modul dalam arsitektur hadoop kadang di sebut juga sebagai Ekosistem Hadoop.
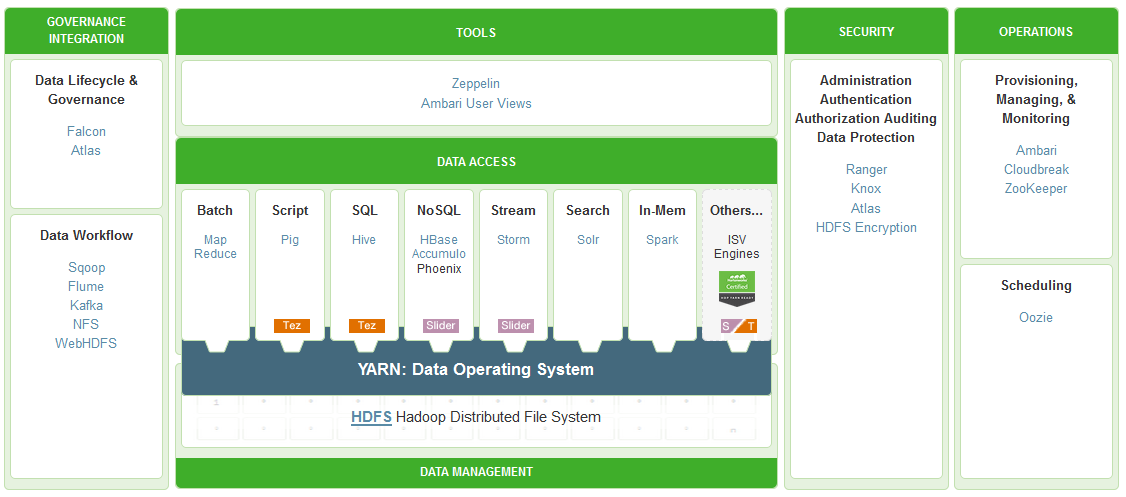 |
| Contoh Ekosistem Hadoop - Hortonwork |
5. Cara kerja Hadoop
 |
| Cara Kerja Hadoop |
5.a Bagaimana cara kerja HDFS
Sebuah kluster HDFS terdiri dari NameNode, yang mengelola metadata dari kluster, dan DataNode yang menyimpan data/file. File dan direktori diwakili pada NameNode oleh inode. Inode menyimpan atribut seperti permission, modifikasi dan waktu akses, atau kuota namespace dan diskspace.Isi file dibagi menjadi blok-blok file( biasanya 128 MB), dan setiap blok file tersebut direplikasi di beberapa DataNodes. Blok file disimpan pada sistem file lokal dari DataNode.
Namenode aktif memonitor jumlah salinan/replika blok file. Ketika ada salinan blok file yang hilang karena kerusakan pada DataNode, NameNode akan mereplikasi kembali blok file tersebut ke datanode lainnya yang berjalan baik. NameNode mengelola struktur namespace dan memetakan blok file pada datanode.
 |
| Cara kerja HDFS |
5.b Bagamana cara kerja MapReduce
MapReduce bertugas membagi data yang besar ke dalam potongan lebih kecil dan mengatur mereka kedalam bentuk tupel untuk pemrosesan paralel. Tupel adalah kombinasi antara key dan value-nya, dapat disimbolkan dengan notasi : "(k1, v1)". Dengan pemrosesan bersifat paralel tersebut, tentunya akan meningkatkan kecepatan dan keandalan komputasi pada sistem klustering.MapReduce terdiri atas tiga tahap, yaitu tahap map, shuffle, dan terakhir reduce. Shuffle dan reduce digabungkan kedalam satu tahap saja yaitu tahap reduce.
1. Map berfungsi memproses data inputan yang umumnya berupa file yang tersimpan dalan HDFS (dapat di baca di Sistem file terdistribusi), inputan tersebut kemudian diubah menjadi tuple yaitu pasangan antara key dan value-nya.
2. Tahap reduce, memproses data inputan dari hasil proses map, yang kemudian dilakukan tahap shuffle dan reduce yang hasil data set baru-nya disimpan di HDFS kembali.
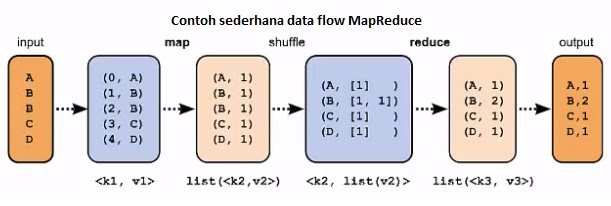 |
| Cara kerja MapReduce |
5.c Bagaimana cara kerja Yarn
Tujuan awal Yarn adalah untuk memisahkan dua tanggung jawab utama dari JobTracker/TaskTracker menjadi beberapa entitas yang terpisah.- Global ResourceManager di node master, yang berfungsi mengatur semua resource yang digunakan aplikasi dalam sistem.
- ApplicationMaster di setiap aplikasi, yang berfungsi untuk negosiasi resource dengan ResourceManager dan kemudian bekerja sama dengan NodeManager untuk mengeksekusi dan memonitor tasks
- NodeManager di Agen-Framework setiap node slave, yang bertanggung jawab terhadap Container, dengan memantau penggunaan resource/sumber daya dari container(cpu, memori, disk, jaringan ) dan melaporkannya pada ResourceManager
- Container di setiap aplikasi yang jalan di NodeManager, sebagai wadah penyimpanan data/file
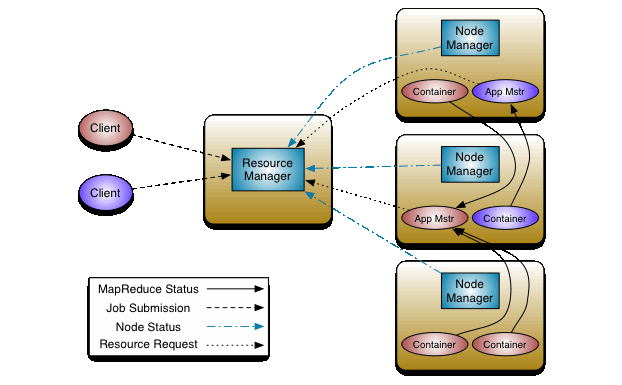 |
| Cara kerja YARN |
6. Vendor hadoop yang ada di pasaran
Tentu kurang lengkap rasanya jika kita tidak menyertakan informasi tentang vendor hadoop yang beredar di pasaran saat ini.Dengan melihat vendor-vendor besar seperti IBM, Microsoft, Amazon yang ikut bermain di dalam menyediakan solusi Big data dengan Hadoop, dapat kita simpulkan bahwa solusi big data dengan hadoop bisa jadi hal yang sangat menjanjikan di masa yang akan datang.
Berikut ini Top 10 Vendor yang menyediakan solusi Big Data dengan hadoop, yang dipaparkan oleh "Bernard Marr" pada artikel di situsnya.
- IBM
- Cloudera
- Amazon Web Service
- Hortonworks
- MapR
- Microsoft HDInsight
- Intel Distribution for Apache Hadoop
- Datastax Enterprise Analytics
- Teradata Enterprise Access for Hadoop
- Pivotal HD
7. Cara Install/Setup Hadoop
Setelah mengetahui beberapa konsep dasar hadoop, saat-nya kita mempersiapkan environment untuk kita mempraktekkan.Cara setup lab termudah adalah dengan menggunakan paket virtual yang biasanya sudah disiapkan oleh sebagian besar vendor hadoop, untuk contoh setup hadoop kali ini, saya gunakan adalah versi free dari Hortonworks.
Berikut ini langkah-langkah persiapan lab dari Hadoop Hortonworks :
1. Download dan Install VMware Player
Dapat didownload di situs VM Ware berikut.
 |
| Download VMWare Player |
Untuk cara-cara instalasinya sangat mudah, dapat dilakukan bahkan oleh orang awam sekalipun. Yaitu cukup dijalankan file installer hasil download tersebut, dan cukup lanjutkan sampai proses instalasi selesai.
2. Download dan load SandBox dari Hortonworks yang sudah termasuk hadoop di dalamnya.
Dapat didownload di Situs Hostonworks berikut.
3. Tambahkan dan hidupkan image dari SandBox menggunakan VMWare Player
4. Environment untuk uji coba sudah tersedia.
Demikian artikel ini saya tulis, semoga dapat memudahkan pemahaman rekans tentang apa itu hadoop.
Salam kenal,
ReplyDeleteTulisan anda tentang hadoop sangat menarik. Saya juga menuliskan opini singkat saya mengenai hadoop di blog saya:
http://tiny.cc/hadoop-blog-rizky
Jika ingin dikomentari, silahkan.
tulisan yg sangat bermanfaat.terima kasih
ReplyDeletemantabb...
ReplyDeleteWah keren banget mas, singkat dan jelas. makasih banyak mas
ReplyDeletemantap, makasih infonya.
ReplyDeletemakasih mas
ReplyDeleteJazakalloh smoga barokag artikelnya, Ane jd pingin belajar hadoop lebih dalam gan, ada situs tutorial lengkapnya gk gan.? Atau lngsung kursus hadoop di bandung or jakarta ada gk ya.? hehe.,
ReplyDeleteAtau
Sangat bermanfaat.. ternyata ini penjelasan yang selama ini saya. Cari..
ReplyDeleteThanks share knowledgenya... susah memahaminya, terlebih lebih banyak sumber asing
ReplyDeleteThank you gan sangat bermanfaat sekali pembahasannya. tapi masih kurang paham soal hadoop. apa ini fokus di infrastruktur nya saja atau lebih ke ERP seperti SAP dan Oodo
ReplyDeleteMampir juga ke tempat ane ya gan. Membahas jaringan komputer dan virtualization.
Andre Networking
Assalamualaikum, kebetulan saya sedang menyusul makalah tentang Hadoop, dan penjelasan ini sangat mudah dipahami namun saya memerlukan referensi buku untuk dicantumkan d daftar pustaka. Apakah saya boleh tahu penulis mengambil dari referensi buku yg berjudul apa dan siapa penulisnya?
ReplyDeleteGreat blog created by you. I read your blog, its best and useful information. You have done a great work. Super blogging and keep it up. Hadoop admin Online Training
ReplyDelete.
Sangat membantu, sy tadinya bingung apa itu hadoop...dan skrg mulai dpt pencerahan. Terimakasih, artikelnya sangat bermanfaat.
ReplyDelete2019 masih belajar, anw maksih ilmunya semgoa berkah.
ReplyDeleteTerima kasih atas sharingnya mas bro, jadi tau apa itu hadoop
ReplyDeletegood job gan
ReplyDeleteisolasi double tape hp